PaStA and Patchwork
The following is a brief report of my project carried out as a part of the Google Summer of Code programme.
The primary goal of the project was to leverage PaStA’s analyses capabilities in Patchwork. Concretely, Patchwork has the ability to relate patches to each other. Through this project I use PaStA to form these relations in Patchwork. I have developed the tooling and infrastructure both in PaStA and Patchwork necessary for the two applications to interface with each other.
The integration between PaStA and Patchwork can broadly be divided into a three step process:
- Share Patchwork’s data in the form of patches with PaStA.
- Carry out analyses in PaStA to form relations in a format suitable for ingestion by Patchwork.
- Ability to import the relations generated by PaStA into Patchwork.
I will briefly go through each of these steps and their implementation as a part of this project. Skip to the section on “End to end setup” if you are only interested in how to make it work.
1. Getting patches into PaStA
For PaStA to carry out analyses on the patches stored in Patchwork we need to get the patches into PaStA first. Some approaches to this problem that were considered are:
- Using a public inbox tracked by both PaStA and Patchwork.
- Dumping patches from Patchwork in the form of raw mboxes
- Using Patchwork’s API to fetch patches.
Option 1 although attractive, was not chosen as Patchwork does not have native support to work with public inboxes. Another important drawback of this option is that Patchwork identifies patches through a unique identifier. This unique identifier is associated to a patch once it enters Patchwork. Since we want to communicate the results of analyses back to Patchwork, it is essential that we maintain these patchwork ids in PaStA too. Using the other options enables us to do this.
Both option 2 and 3 were implemented to tackle different usecases.
Usecase 1: Initial import of patches into PaStA
When integrating PaStA with an existing mailing list, it would be required to get a lot of historical patch data into PaStA. Such an import will not be feasible through Patchwork’s API. Hence we give the capability of an initial import. Here the raw mbox of patches from Patchwork is specified to PaStA and it imports the patches using the raw mbox.
Usecase 2: Differential imports
Once the initial import has been carried out, new patches arriving in Patchwork will be pulled by PaStA at periodic intervals. Note that we only want to pull the newly arriving patches and not the entire set of patches. Since the number of patches arriving every time period (in the order of hours or days) is manageable, we can import these patches through Patchwork’s API. We track the set of patches already in PaStA and import all the patches in Patchwork that are not in PaStA.
The setup between PaStA and Patchwork has been documented here
Code implementing this functionality
- Handle Patchwork archives specially and track patchwork ids in index
- Refactoring
- Read configuration options for Patchwork
- Pull patches from patchwork
- Documentation
2. Analyses in PaStA and forming relations
The infrastructure to analyse patches was already in place in PaStA. However
PaStA generates patches in the from of a patch groups file which contains lines
of space separated message ids denoting related patches. (It also contains
references to upstream commits which we will ignore for now). In order to push
these relations into Patchwork we need to use the patchwork id described
above that is used by Patchwork to uniquely identify a patch. For this purpose
the form_patchwork_relations executable was added. This executable takes as
input the patch groups file generated by PaStA and translates the message ids
within it to Patchwork ids.
Code implementing this functionality
3. Getting patch relations into Patchwork
For the final step we need to push the results of PaStA’s analyses i.e the
newly formed patch relations to Patchwork. This was achieved by introducing a
new Django management command: parserelations. This command takes as input
the patch groups file (with Patchwork ids) generated in the previous steps and
replaces the existing relations in Patchwork (if any) with the ones defined in
the patch groups file.
Code implementing this functionality
An end to end setup
With the tooling and infrastructure introduced, it is possible to have an end to end setup of PaStA and Patchwork, where PaStA can generate relations for Patchwork.
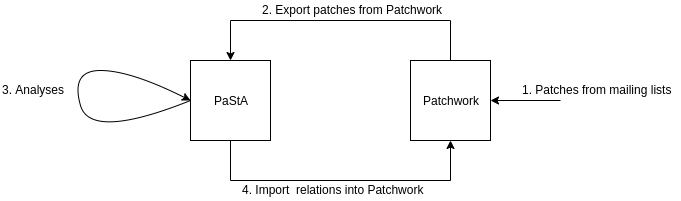
After the initial import of patches from Patchwork to PaStA, the above flow can be run as a script periodically, for instance as a cron job.
The commands executed by the script at each stage can be outlined as follows:
-
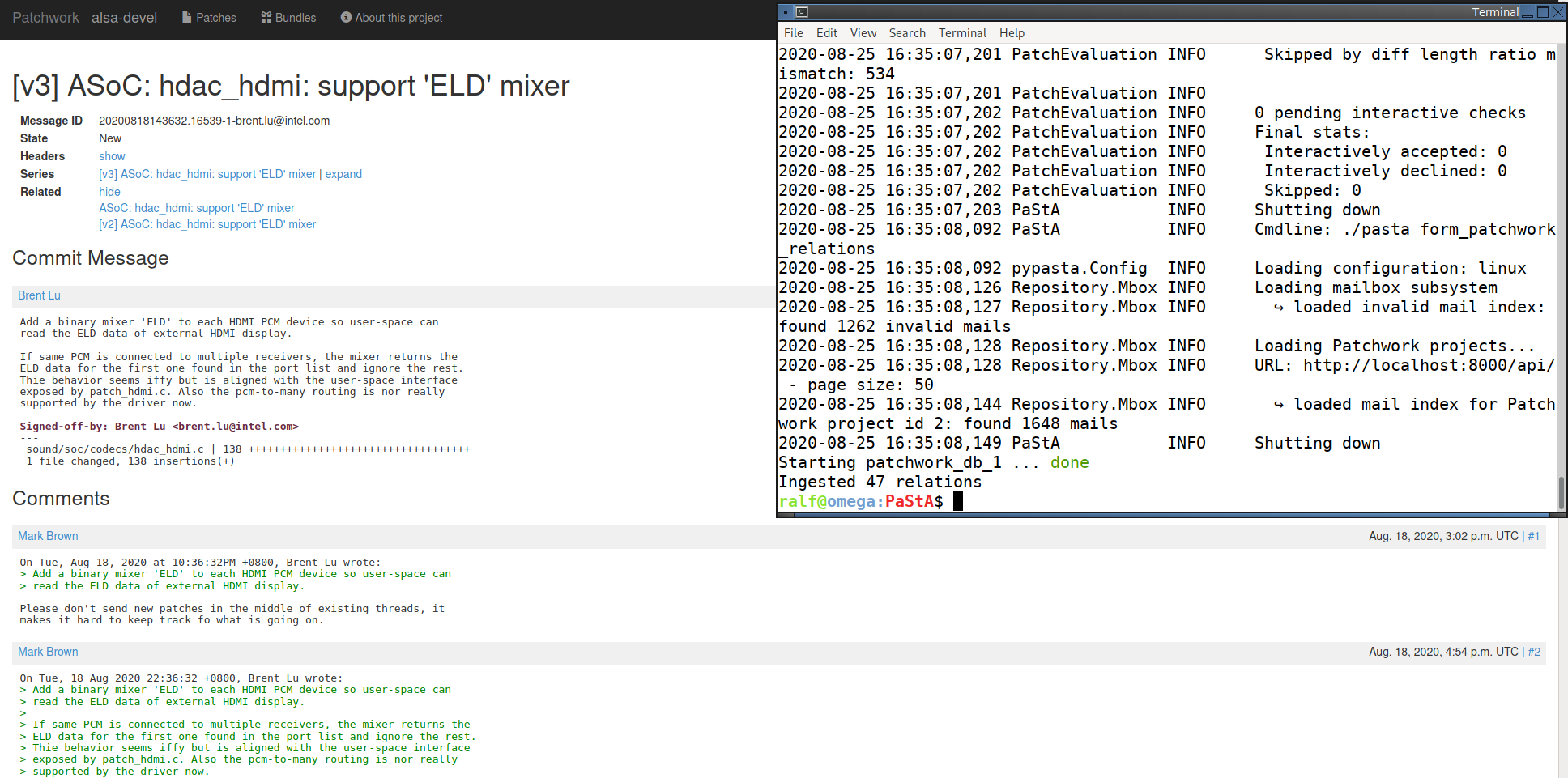
Export patches from Patchwork and import into PaStA:
In Patchwork:
$ ./manage.py dumparchive <list-id>In PaStA (after appropriately setting up the configuration files):
$ ./pasta sync -mbox - Analyses in PaStA
$ ./pasta analayse rep $ ./pasta rate $ ./pasta form_patchwork_relations - Importing relations in Patchwork
$ ./manage.py replacerelations <path-to-patch-groups-file-from-previous-step>
Code implementing this functionality
Future Work
- Along with forming relations between patches PaStA can also associate a relation with the upstream commits in the repo for that relation. We can leverage these commit references too in Patchwork.
- The
replacerelationscommand replaces all the existing relations. This is not ideal, and it would be nice to somehow reconcile the existing relations in Patchwork with the new relations from PaStA. Further the relations API in Patchwork could be used to add new relations. - PaStA’s analyses phase can be optimised by doing a differential analyses. A patch for this has been introduced for discussion and can be seen here.
Acknowledgements
I want to thank all my mentors, especially Lukas, Ralf and Daniel. Lukas and Ralf for being available inspite of their busy schedules. Their input was invaluable throughout the project. Daniel was very patient while reviewing my patches sent to the Patchwork mailing list.
Note: Some rough notes about PaStA and Patchwork can also be found in my braindump